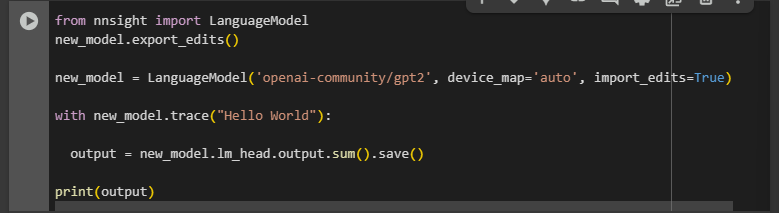
Hi, the library is great, and the new release allows for a lot of things. Thank you for the great work!
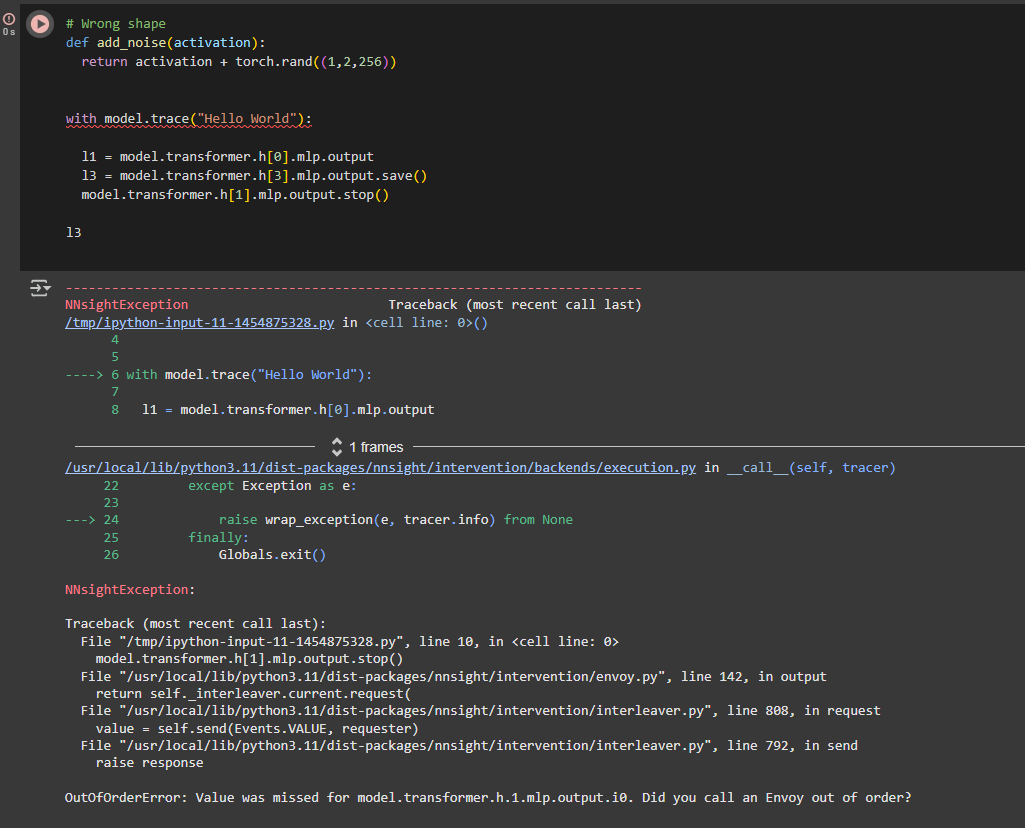
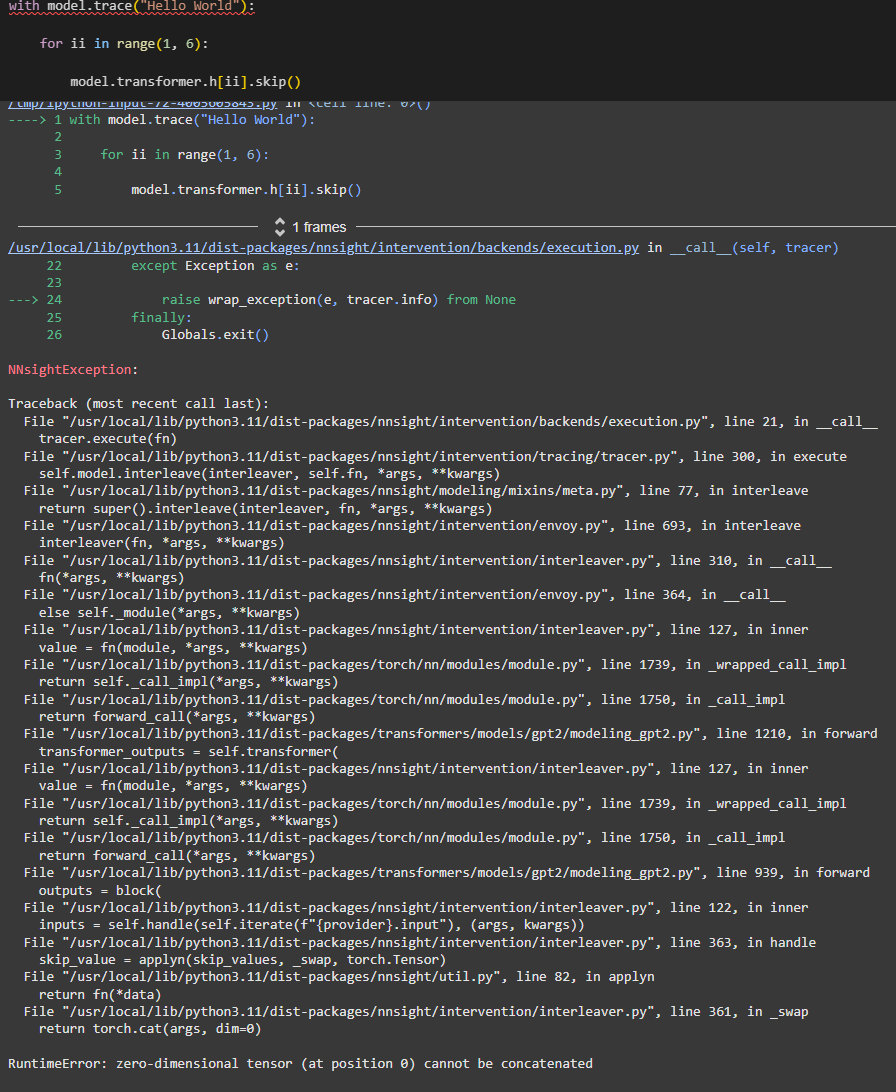
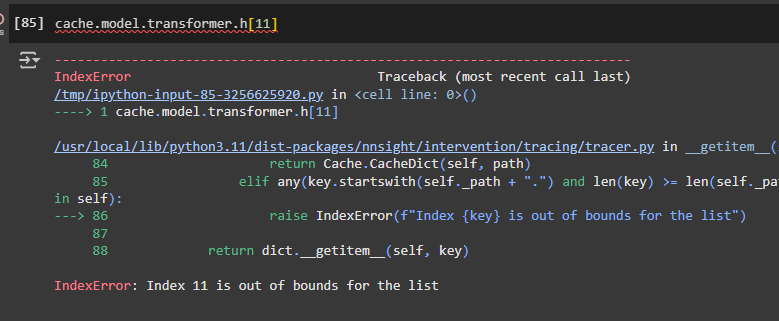
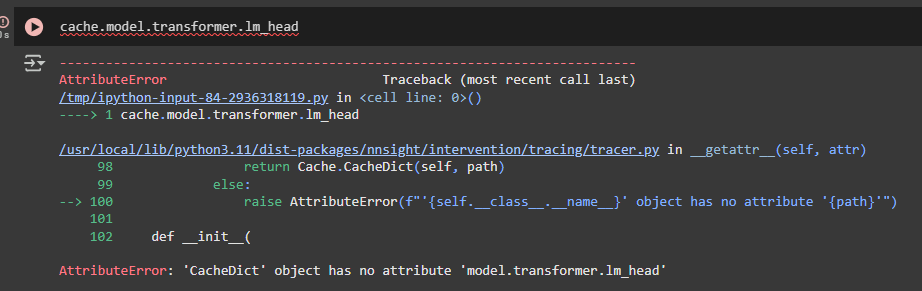
I stumbled upon what seems to be a bug, when I execute the following lines in version 0.4.8, it goes smoothly, but with the 0.5.0.dev2, I obtain the following error:
Do you have any idea of the cause? It happens with other Bert IDs. Or when given a Bert instance directly.
from nnsight import LanguageModel
model = LanguageModel('bert-base-uncased')
AttributeError: BertAttention(
(self): BertSdpaSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
) has no attribute _handle_overloaded_mount
Update
I did some more tests:
from nnsight import LanguageModel
from transformers import (
AutoModelForCausalLM,
AutoModelForSeq2SeqLM,
AutoModelForSequenceClassification,
)
ALL_MODEL_LOADERS = {
"hf-internal-testing/tiny-random-albert": AutoModelForSequenceClassification,
"hf-internal-testing/tiny-random-bart": AutoModelForSequenceClassification,
"hf-internal-testing/tiny-random-bert": AutoModelForSequenceClassification,
"hf-internal-testing/tiny-random-DebertaV2Model": AutoModelForSequenceClassification,
"hf-internal-testing/tiny-random-distilbert": AutoModelForSequenceClassification,
"hf-internal-testing/tiny-random-ElectraModel": AutoModelForSequenceClassification,
"hf-internal-testing/tiny-random-roberta": AutoModelForSequenceClassification,
"hf-internal-testing/tiny-random-t5": AutoModelForSeq2SeqLM,
"hf-internal-testing/tiny-random-gpt2": AutoModelForCausalLM,
"hf-internal-testing/tiny-random-gpt_neo": AutoModelForCausalLM,
"hf-internal-testing/tiny-random-gptj": AutoModelForCausalLM,
"hf-internal-testing/tiny-random-CodeGenForCausalLM": AutoModelForCausalLM,
"hf-internal-testing/tiny-random-FalconModel": AutoModelForCausalLM,
"hf-internal-testing/tiny-random-Gemma3ForCausalLM": AutoModelForCausalLM,
"hf-internal-testing/tiny-random-LlamaForCausalLM": AutoModelForCausalLM,
"hf-internal-testing/tiny-random-MistralForCausalLM": AutoModelForCausalLM,
"hf-internal-testing/tiny-random-Starcoder2ForCausalLM": AutoModelForCausalLM,
}
for id, autoclass in ALL_MODEL_LOADERS.items():
try:
LanguageModel(id, automodel=autoclass)
except AttributeError:
print(f"Failed {id.split('-')[-1]}")
continue
Failed bert
Failed DebertaV2Model
Failed ElectraModel
Failed roberta